Identification des preuves dans des données hétérogènes à l'aide du clustering
2022-04-23
|
Hussam Mohammed1 Centre de recherche en sécurité, communications et réseaux Université de Plymouth hussam.mohammed@plymouth.ac |
Nathan Clarke2 Centre de recherche en sécurité, communications et réseaux Université de Plymouth N.Clarke@plymouth.ac.uk |
Fudong Li3 Centre de recherche en sécurité, communications et réseaux Université de Plymouth fudong.li@port.ac.uk |
RÉSUMÉ
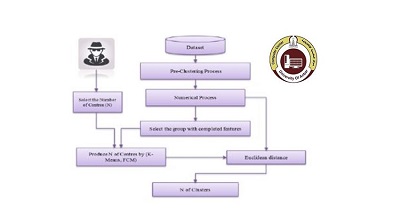
La criminalistique numérique fait face à plusieurs défis lors de l'examen et de l'analyse des données en raison d'une gamme croissante de technologies à la disposition des gens. Les enquêteurs se retrouvent à devoir traiter et analyser manuellement de nombreux systèmes (par exemple, PC, ordinateur portable, smartphone) dans une seule affaire. Malheureusement, les outils actuels tels que FTK et Encase ont une capacité limitée à automatiser la recherche de preuves. En conséquence, un lourd fardeau est imposé à l'enquêteur pour à la fois trouver et analyser les artefacts de preuve dans un environnement hétérogène. Cet article propose une approche de regroupement basée sur les algorithmes Fuzzy C-Means (FCM) et K-means pour identifier les fichiers de preuve et isoler les fichiers non liés en fonction de leurs métadonnées. Une série d'expériences utilisant des cas criminels réels hétérogènes ont été menées pour évaluer l'approche. Dans chaque cas, diverses catégories de métadonnées ont été créées en fonction des systèmes de fichiers et des applications. Les résultats ont montré que le regroupement basé sur les systèmes de fichiers a donné les meilleurs résultats de regroupement des artefacts de preuve en seulement cinq clusters. La proportion à travers les cinq clusters était de 100 % en utilisant de petites configurations de FCM et K-means avec moins de 16 % des artefacts non probants dans tous les cas -- représentant une réduction de l'analyse de 84 % des fichiers bénins. En termes d'applications, la proportion de preuves était de plus de 97 %, mais la proportion de fichiers bénins était également relativement élevée sur la base de petites configurations. Cependant, avec une grande configuration, la proportion de fichiers bénins est devenue très faible, inférieure à 10 %. Prioriser avec succès de grandes proportions de preuves et réduire le volume de fichiers bénins à analyser réduit le temps nécessaire et la charge cognitive de l'enquêteur.
Lien.....